
In this series, we are building an agentic KYC workflow for high-net-worth onboarding piece by piece.
- The KYC Orchestrator (this post)
I also built a working prototype in Python to demonstrate this architecture. You can find the link to the prototype here.
Imagine a conductor standing in front of a full orchestra.
Every musician is ready, but the music does not start until the conductor gives the signal.
The conductor decides who starts, who joins next, and how the entire piece comes together.
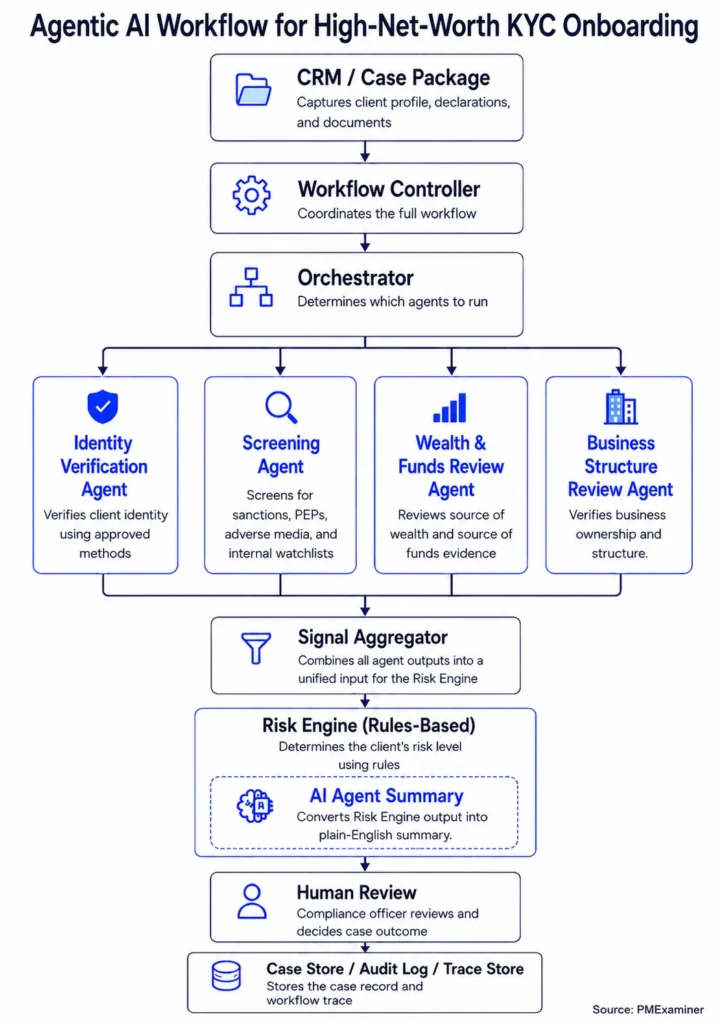
That is what the Orchestrator does in a KYC workflow.
The Workflow Controller runs the agents. But the Orchestrator decides the agent plan: which agents should run, how they should run, and what information each agent should receive.
To do that, the Orchestrator first receives a structured case package from the Workflow Controller.
For James, that package may look like this:
{
"case_id": "KYC-123",
"declared_profile": {
"full_name": "James Whitmore",
"source_of_wealth": "Sale of private business",
"source_of_funds": "Crypto exchange transfer",
"pep_declared": true
},
"document_refs": [
{
"document_id": "doc_003",
"document_type": "bank_statement",
"document_url": "cloud://kyc-documents/KYC-123/doc_003.pdf",
"extracted_facts_url": "cloud://kyc-extracted-facts/KYC-123/doc_003_facts.json"
}
]
}The case package gives the workflow one structured view of the client’s declared details and supporting document references.
Once the Orchestrator has that view, it can build the agent plan.
The Orchestrator’s plan answers three simple questions:
- Which agents should run?
- How should each agent run?
- What information should each agent receive?
Those three answers decide how the rest of the workflow runs.
To see how this works in practice, let’s compare a simple client with James.
Imagine a client with a high salary, no business ownership, no crypto funds, and no cross-border transactions.
For this client, the Orchestrator creates a simple plan:
{
"agents_to_run": [
"identity_verification_agent",
"screening_agent",
"wealth_and_funds_review_agent"
],
"agents_not_required": [
"business_structure_review_agent"
],
"agent_methods": {
"identity_verification_agent": "government_issued_photo_id_method",
"wealth_and_funds_review_agent": "standard_salary_income_review"
},
"agent_inputs": {
"identity_verification_agent": [
"client identity details",
"government ID",
"proof of address"
],
"screening_agent": [
"client identity details",
"PEP declaration",
"tax residency"
],
"wealth_and_funds_review_agent": [
"declared salary income",
"recent bank statements",
"employment or income details"
]
}
}The Business Structure Review Agent does not run because this client has no business context.
That is the point of the plan. The workflow does not run an agent just because the agent exists.
The agent_methods section tells each agent how to run.
For a client with a simple profile, the Orchestrator tells the Identity Verification Agent to use government-issued photo ID verification.
In Canada, FINTRAC allows different ways to verify a client’s identity. These include photo ID verification, credit file verification, and the dual-process method.
For a simple client, the Orchestrator chooses the government-issued photo ID method because the client’s identity can be verified with standard documents.
The agent_inputs section tells each agent what information and documents it needs to run.
Now compare that with James.
James has declared possible PEP status, sold a private business, has crypto funds, and expects cross-border transactions.
For James, the Orchestrator creates a more detailed plan:
{
"agents_to_run": [
"identity_verification_agent",
"screening_agent",
"wealth_and_funds_review_agent",
"business_structure_review_agent"
],
"agent_methods": {
"identity_verification_agent": "dual_process_method",
"wealth_and_funds_review_agent": "enhanced_wealth_and_funds_review",
"business_structure_review_agent": "business_sale_context_review"
},
"agent_inputs": {
"identity_verification_agent": [
"client identity details",
"government ID",
"proof of address",
"consent records"
],
"screening_agent": [
"client identity details",
"PEP declaration",
"tax residency",
"country exposure"
],
"wealth_and_funds_review_agent": [
"source of wealth declaration",
"source of funds declaration",
"bank statement",
"business sale agreement",
"crypto-related information"
],
"business_structure_review_agent": [
"business sale context",
"business ownership information",
"sale-related records"
]
}
}The Orchestrator includes the Business Structure Review Agent because James’s wealth came from a business sale.
It tells the Identity Verification Agent to use the dual-process method because James’s profile is more complex and the bank needs stronger identity evidence.
It asks the Wealth and Funds Review Agent to run an enhanced review because James’s case includes business sale proceeds and crypto funds.
Why does the Orchestrator create two different plans for two different clients?
Because not every client needs the same agents, methods, or evidence.
For a client with a simple profile, the Orchestrator keeps the plan straightforward. It runs only the agents that are relevant, chooses standard methods, and avoids steps that do not apply to the case. That client can be onboarded faster because the system is not running unnecessary agents.
For a client like James, the Orchestrator builds a more detailed plan. It runs more agents, sends them more information, and asks them to use stronger methods because the case is more complex.
That is the value of the Orchestrator. It helps the workflow treat simple cases simply and complex cases carefully.
Why do we need both a Workflow Controller and an Orchestrator?
Why not let the Workflow Controller decide everything?
Because then the whole workflow becomes harder to manage. The Workflow Controller would have to decide which agents should run, run those agents, handle pauses, call the downstream steps, and record what happened.
And when that happens, the workflow becomes difficult to understand, test, and explain.
In banking, that matters.
If a regulator asks why a case followed a certain path, the bank needs a clear answer. It needs to show the rules it applied, the steps it ran, and why the case moved in that direction.
That becomes much harder when one part of the workflow does everything.
The cleaner design is to separate the two tasks.
The Orchestrator decides the plan.
The Workflow Controller runs it.
And because they are separate, the bank can improve one without changing the other.
For example, if the bank decides that every high-net-worth client with crypto funds now needs enhanced wealth review, the team can update the Orchestrator. The Orchestrator builds a different plan for those clients, but the Workflow Controller still runs the plan the same way.
If the bank changes how cases pause and resume, the team updates the Workflow Controller. A missing source-of-funds document may create a task for the relationship manager, while a possible PEP match may go to a compliance officer. The Orchestrator stays the same.
That is the benefit of keeping them separate.
The workflow becomes easier to update, test, and explain to a regulator later.
That is how the agentic KYC workflow gets direction.
The Orchestrator decides which agents should run, how they should run, and what information they should receive.
Like the conductor, it does not play every instrument. It keeps the workflow moving in the right order.
In the next post, we look at the first specialist agent in the workflow: the Identity Verification Agent.